SGCom je navrhnutý tak, aby bol odolný voči rôznym formám výpadkov. Pri svojom štarte sa musí pripojiť k centrále, aby získal konfiguráciu (bez ktorej nevykoná žiadnu akciu), ale potom môže pracovať aj v prípade, že stratí s centrálou na nejaký čas kontakt. Je robustný aj v prípade, že nedokáže vykonať zber dát, o čom informuje centrálu a poskytuje mechanizmy, ako neskôr dáta opätovne získať. Životný cyklus ilustruje nasledujúci obrázok a možno ho tiež popísať v nasledovných krokoch.
Obrázok 3 Ilustrácia životného cyklu
- Štart aplikácie, spracovanie parametrov príkazového riadku, ktoré okrem iného obsahujú adresu pre pripojenie sa ku D2000 kernelu, prihlasovacie údaje a adresu tzv. „bodu prvého kontaktu".
- Vykonanie údržby modulu DataStorage:
- Vymazanie záznamov starších ako 90 dní. Úloha sa opakuje každých 24 hodín.
- Odstránenie označenia číslom transakcie zo všetkých záznamov (podrobnosti v kroku 7).
- Pripojenie ku D2000 kernelu centrály. SGCom sa pokúša získať D2Japi Session, ktorá bude v DODM reprezentovaná objektom s názvom v tvare SGCOM1.SGC. V prípade neúspechu sa pokus o pripojenie opakuje každých 30 sekúnd.
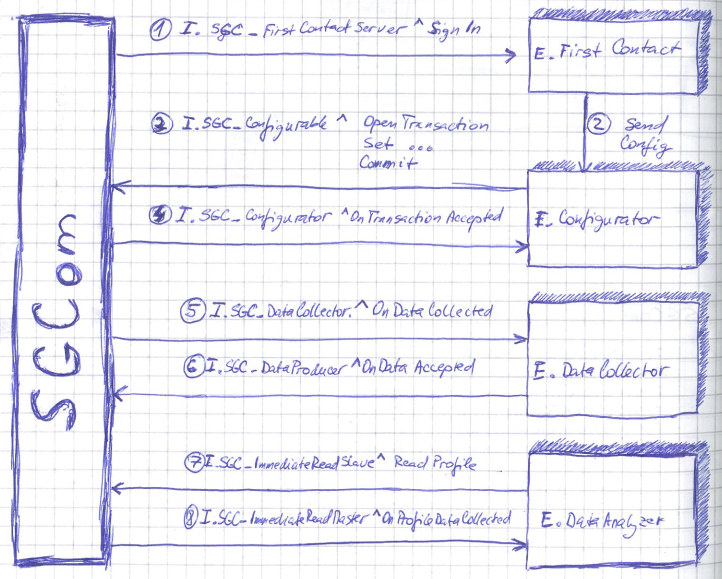
- Prihlásenie sa do „bodu prvého kontaktu" Adresa objektu je definovaná parametrom z príkazového riadku –f., čo je inštancia objektu typu D2000 Event, ktorá implementuje rozhranie I.SGC_FirstContactServer. Prihlási sa volaním RPC SignIn s hodnotou parametra _name nastavenou na meno procesu (z príkazového riadku). RPC je asynchrónne a zakladá aplikačne riadenú transakciu, ktorá zabezpečí, že sa buď SGCom alebo centrála dozvie, keď jej partner havaruje.
- Centrála na nadviazanie prvého kontaktu reaguje tým, že odošle do SGCom-u novú konfiguráciu, resp. zmení existujúci. D2000 Event, ktorý riadi zasielanie konfigurácie musí implementovať rozhranie I.SGC_Configurator, SGCom pre prijatie implementuje rozhranie I.SGC_Configurable.
- Prenos konfigurácie je transakčný. Všetky zmeny sú buď v poriadku a prijaté ako celok, alebo sú všetky zamietnuté a konfigurácia je ponechaná v pôvodnom stave. Postupnosť krokov je nasledovná:
- Otvorenie transakcie: I.SGC_Configurable^OpenTransaction
- Odoslanie zmien: I.SGC_Configurable^Set* a Delete*.
- Príkazy je nutné zadávať v takom poradí, aby nebola v žiadnom okamihu porušená referenčná integrita konfiguračnej databázy.
- Commit transakcie: I.SGC_Configurable^Commit
- Potvrdenie prijatia zmien I.SGC_Configurator^OnTransactionAccepted, alebo zamietnutie zmien I.SGC_Configurator^OnTransactionDenied so zoznamom chýb v parametri.
- Alternatívne môže byť transakcia zrušená zo strany centrály volaním I.SGC_Configurable^Rollback, čo SGCom potvrdí I.SGC_Configurator^OnTransactionRolledBack. Transakcia je automaticky zrušená aj v prípade, že sa preruší aplikačne riadená konverzácia.
- Prenos konfigurácie je transakčný. Všetky zmeny sú buď v poriadku a prijaté ako celok, alebo sú všetky zamietnuté a konfigurácia je ponechaná v pôvodnom stave. Postupnosť krokov je nasledovná:
- SGCom podľa aktuálnej konfigurácie SGCom nastaví svoj harmonogram úloh – pre každú entitu PeriodicEvent vytvorí zvlášť záznam a naplánuje jej vykonanie.
- Keď nastane časový okamih, na ktorý je naplánovaná periodická udalosť, SGCom prezrie aktuálnu konfiguráciu a začne vykonávať všetky súvisiace úlohy. Do modulu TaskExecutor vloží do príslušných front úlohy na zber a odovzdávanie dát, ktoré TaskExecutor následne vykoná. Vykonanie úloh, ktoré si vzájomne nekonkurujú je paralelné. (Pozn.: vzájomne si konkurujú dve úlohy, ktoré sú vykonané na tom istom logickom zariadení a tiež úlohy, ktoré obsluhujú logické zariadenia pripojené tou istou komunikačnou linkou. Zber a odovzdávanie dát si vzájomne nekonkuruje.)
Zber dát každej jednej veličiny, či už úspešný alebo neúspešný, končí tým, že je výsledok zaznamenaný do modulu DataStorage. Pri úspešnom zbere je to zoznam hodnôt s časovými značkami, pri neúspešnom je to kód a popis chyby, tiež s časovou značkou.
Odovzdanie hodnôt centrále prebieha po jednotlivých logických zariadeniach a jednotlivých veličinách (DataPoint). Každé odovzdanie predstavuje samostatnú transakciu a až keď centrála potvrdí úspešné prevzatie hodnôt, sú dáta odstránené z DataStorage. Odovzdanie pre jedno logické zariadenie a veličinu pozostáva z nasledujúcich krokov:- Vygenerovanie unikátneho ID transakcie.
- Všetky záznamy pre dané logické zariadenie a veličinu sú označené číslom transakcie. (V prípade, že predchádzajúca transakcia neskončila, sú označené len nové záznamy.)
- Hodnoty a časové značky označených záznamov sú odoslané volaním I.SGC_DataCollector^OnDataCollected.
- Po spracovaní dát je transakcia ukončená volaním I.SGC_DataProducer^OnDataAccepted.
- Záznamy označené príslušným číslom transakcie sú vymazané z DataSorage-u.
(Pozn.: RPC komunikácia prebieha v rámci aplikačne riadenej transakcie, takže ak spracovanie odovzdaných dát z nejakého dôvodu zlyhá, SGCom sa túto skutočnosť dozvie a transakcia sa zruší. Dáta zostanú v DataStorage-i do nasledujúceho plánovaného odovzdávania dát a označenie číslom transakcie sa odstráni.)
- Centrála môže kedykoľvek po odoslaní konfigurácie zadať príkaz na vykonanie „okamžitej" úlohy. Najčastejšie sa vykonáva čítanie archivovaných dát meraných veličín za obdobie, pre ktoré v centrále chýbajú dáta, ale tiež nastavenie presného času v meračoch a iné. Príkazy sú riadené párovými rozhraniami I.SGC_ImmediateReadMaster – Slave, I.SGC_SetRTCMaster – Slave, I.SGC_ConsumerDisconnectMaster – Slave, kde centrála implementuje Master rozhranie a SGCom implementuje Slave. Všetky príkazy prebiehajú v režime aplikačne riadených konverzácií ale vždy pozostávajú len s jednoduchej výmeny príkaz – oznámenie výsledku.
- Ak SGCom stratí spojenie s centrálou, naďalej pokračuje vo vykonávaní plánovaných úloh, ako je popísané v bode 7. Zber dát prebieha bez zmeny, všetky pokusy o odovzdanie zlyhajú a zozbierané dáta sa preto zhromažďujú v DataStorage-i až dovtedy, kým sa nepodarí spojenie obnoviť a dáta odovzdať. Po nadviazaní nového spojenia pokračuje vykonávanie bodom 4.
Modul TaskExecutor
Modul TaskExecutor je zodpovedný za vykonávanie všetkých úloh, ktoré vyplývajú z konfigurácie ako aj všetkých „okamžitých" úloh. Používa pri tom zoznam pravidiel, ktoré určujú, ktoré úlohy je možné vykonať paralelne. Úlohám, ktoré paralelne vykonať nemožno (lebo si vzájomne konkurujú v prístupe k meračom), definuje poradie, v akom sa vykonajú tak, aby bola maximalizovaná priepustnosť. Zároveň tieto pravidlá definujú časové okná, počas ktorých komunikácia s niektorými meračmi nie je možná – po ukončení spojenia nie je možné určitý čas nadviazať nové spojenie.
Pri vytváraní konfigurácie je potrebné brať do úvahy tieto pravidlá, ako aj čas, ktorý trvá vytvorenie spojenia, vykonanie jednotlivých úloh, zatvorenie spojenia a výluka spojenia, aby nebolo naplánovaných viac úloh, ako je možné obslúžiť.
Pri obsluhe meračov sa vykonávanie úloh riadi nasledujúcimi pravidlami:
- Nie je možné vytvoriť súčasne dve alebo viac spojení s jedným logickým zariadením.
- Nie je možné vytvoriť súčasne spojenia na dve logické zariadenia, ktoré sú pripojené tou istou komunikačnou linkou (v konfigurácii zdieľajú tú istú entitu Connector).
- Ak existuje aktívne spojenie k nejakému logickému zariadeniu, musia sa vykonať všetky úlohy, ktoré sú pre dané zariadenie zaradené do fronty úloh skôr, ako bude spojenie ukončené (z optimalizačných dôvodov). Úlohy sú z fronty vyberané politikou „first-came-first-served".
- Po vykonaní poslednej úlohy z fronty zostáva spojenie k logickému zariadeniu aktívne ešte 10 sekúnd Dĺžku čakania na novú úlohu je možné upraviť parametrom z príkazového riadku -n.. Ak je v tomto časovom intervale do fronty zaradená nová úloha, je tiež vykonaná a spojenie sa opäť ponecháva aktívne ďalších 10 sekúnd. Až keď nepribudne žiadna nový úloha, je spojenie uzatvorené. (Aby bolo možné efektívne obslúžiť rýchlo sa opakujúce úlohy.)
- Po zrušení spojenia nie je možné vytvoriť nové spojenie na žiadne z logických zariadení, ktoré sú pripojené použitou komunikačnou linkou po dobu 20 sekúnd Dĺžku ochranného intervalu je možné zmeniť parametrom z príkazového riadku -s.. (Lebo by bolo spojenie aj tak odmietnuté a trvalo by to dlhšie, kým by sa spojenie podarilo opäť nadviazať.)
- Po uplynutí 20-sekundového ochranného intervalu je obslúžené ďalšie logické zariadenie čakajúce vo fronte.
- Ak je pokus o vytvorenie spojenia s nejakým logickým zariadením neúspešný 3-krát po sebe Počet pokusov je možné zmeniť parametrom z príkazového riadku -r., považuje sa za odpojené – stav HardError – a spojenie s ním nie je možné nadviazať po dobu nasledujúcich 5 minút Dĺžku trvania HardError stavu je možné upraviť parametrom z príkazového riadku -d.. Všetky úlohy vo fronte, ktoré mali byť vykonané na tomto zariadení, sú stornované, ako aj všetky nové úlohy po dobu trvania HardError stavu. Po uplynutí tejto lehoty je možné sa opäť pokúsiť pripojiť k zariadeniu.
- Všetky úlohy, ktoré si vzájomne nekonkurujú, je možné vykonať paralelne vláknami príslušného ThreadPool-u. Počet vlákien v ThreadPool-e je maximálne 512 Maximálny počet vlákien je možné upraviť parametrom z príkazového riadku -t., ale dynamicky sa mení podľa aktuálnych potrieb.
Pridať komentár